
Todo lo que querías saber sobre las Data Clean Rooms (y no te atrevías a preguntar)
Pese a que el término "Data Clean Room" se ha hecho muy popular en el sector AdTech en los últimos años, es uno de los temas que menos comprenden los profesionales de la industria. Las Data Clean Rooms (y la colaboración de datos en general) serán una tecnología fundamental en el panorama moderno post cookies.
No obstante, como sucede con muchos conceptos en MarTech y AdTech, entender cómo funciona la tecnología, por qué es importante o qué rol juega puede ser difícil. Por eso, replicamos esta guía escrita por Vincent Niou, fundador de la compañía Skeleton Key, para aclarar todo lo necesario sobre las Data Clean Rooms (o DCRs, por sus siglas en inglés).
Veremos cómo funcionan, cómo es el match de datos dentro de una DCR, cómo conceptualizar casos de uso, las diferentes categorías y algunos otros detalles.
¿Qué son las Data Clean Rooms?
Las Data Clean Rooms son entornos seguros en los que dos (o más) partes pueden cargar los datos de sus usuarios para colaborar en casos de uso mutuamente acordados sin compartir realmente los datos ni comprometer la privacidad de sus usuarios.
¿Por qué se han vuelto importantes?
Una confluencia de factores ha contribuido al auge de las Data Clean Rooms (y la colaboración de datos en general). Algunos de los más destacados incluyen:
Regulación de privacidad de datos y preocupaciones de los usuarios: Con leyes como GDPR y CCPA, y la creciente preocupación social por la privacidad, las Data Clean Rooms respetan la privacidad mientras permiten el uso de datos en marketing.
Declive de los identificadores tradicionales third-party: La desaparición de cookies y otros identificadores 3P ha creado una necesidad de tecnologías alternativas para casos de uso basados en datos.
Fragmentación creciente de medios y datos: La fragmentación en el acceso a medios y datos ha aumentado, impulsada por el valor creciente del first-party data debido al declive de los identificadores cross-site.
Demanda creciente de colaboración de first-party data: A medida que los identificadores third-party pierden viabilidad, la importancia de first-party data crece, y con ello, la colaboración segura entre diferentes partes.
Avances tecnológicos: Mejoras en la computación en la nube, la seguridad de datos y tecnologías encriptadas han hecho posible la creación de Data Clean Rooms que pueden manejar grandes volúmenes de datos manteniendo la privacidad y seguridad.
Cómo funcionan las Data Clean Rooms
Primero, analizaremos cómo funcionan las DCR a nivel general para luego profundizar en elementos y conceptos específicos de las DCR y así reforzar la comprensión.
Configuración
Una DCR se configura cuando múltiples partes acuerdan colaborar con datos. Estas partes pueden incluir marcas, agencias, compañías de medios, walled gardens, y cualquier entidad con first-party data escalable. Una de las partes o empresas crea una instancia de Data Clean Room. Es importante destacar que cada instancia de DCR es única para cada grupo de colaboradores, y aunque puede incluir más de dos partes, en este ejemplo nos enfocaremos en dos para simplificar.
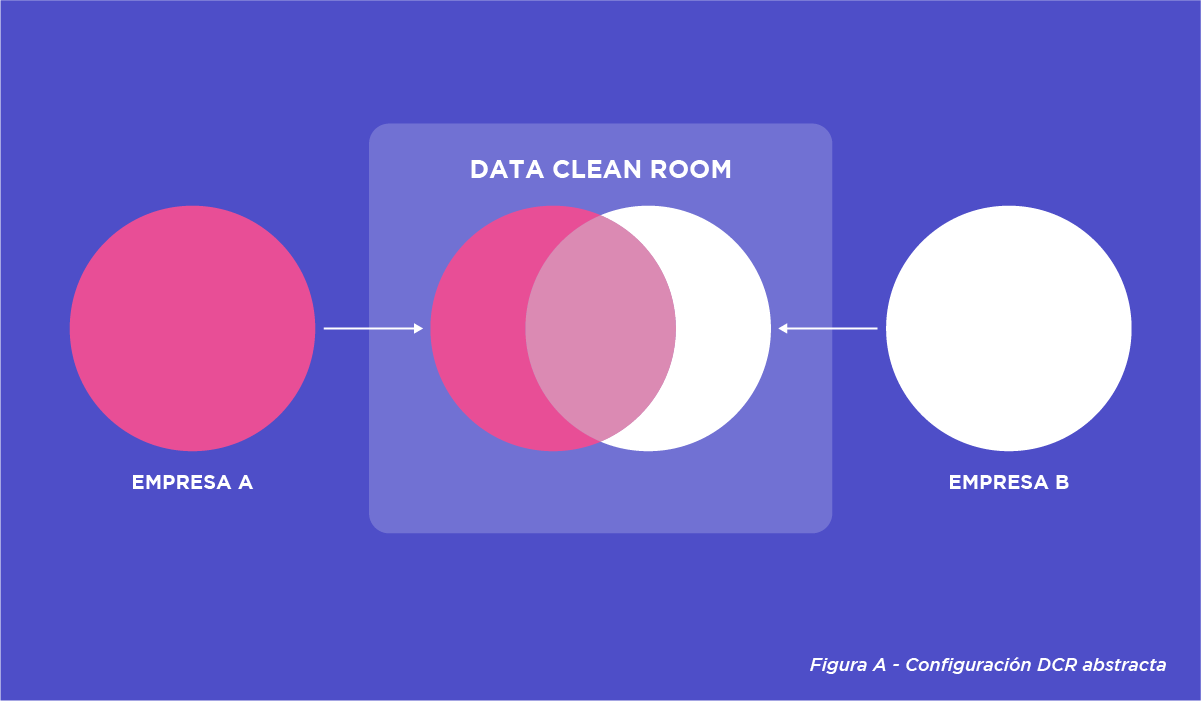
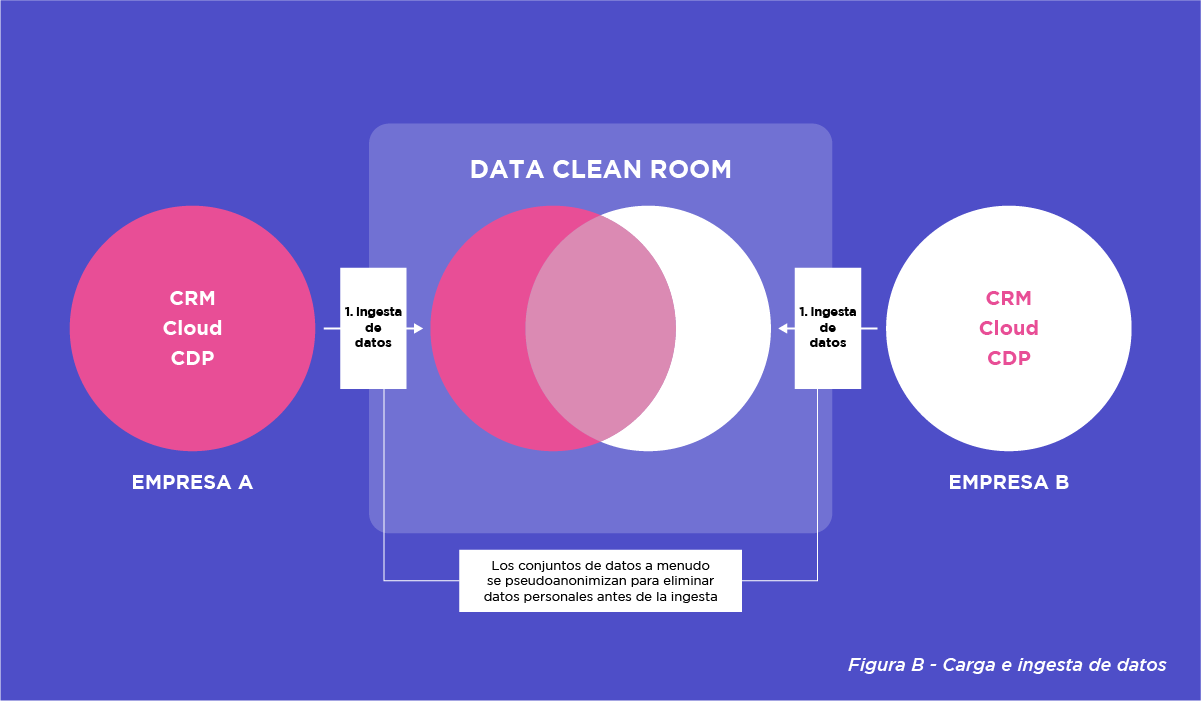
Carga e ingesta de datos
Las partes colaboradoras suben sus conjuntos de datos a la DCR. Estos datos pueden incluir direcciones de correo electrónico, identificadores de dispositivos u otros identificadores first-party, provenientes de donde se almacenan (por ejemplo, CRM, Data Warehouse en la nube, CDP). En esta etapa, los datos suelen ser anonimizados o seudonimizados para proteger las identidades individuales. Por ejemplo, las direcciones de correo electrónico pueden ser cifradas para ocultar la información original, manteniendo la capacidad de hacer match entre los conjuntos de datos.
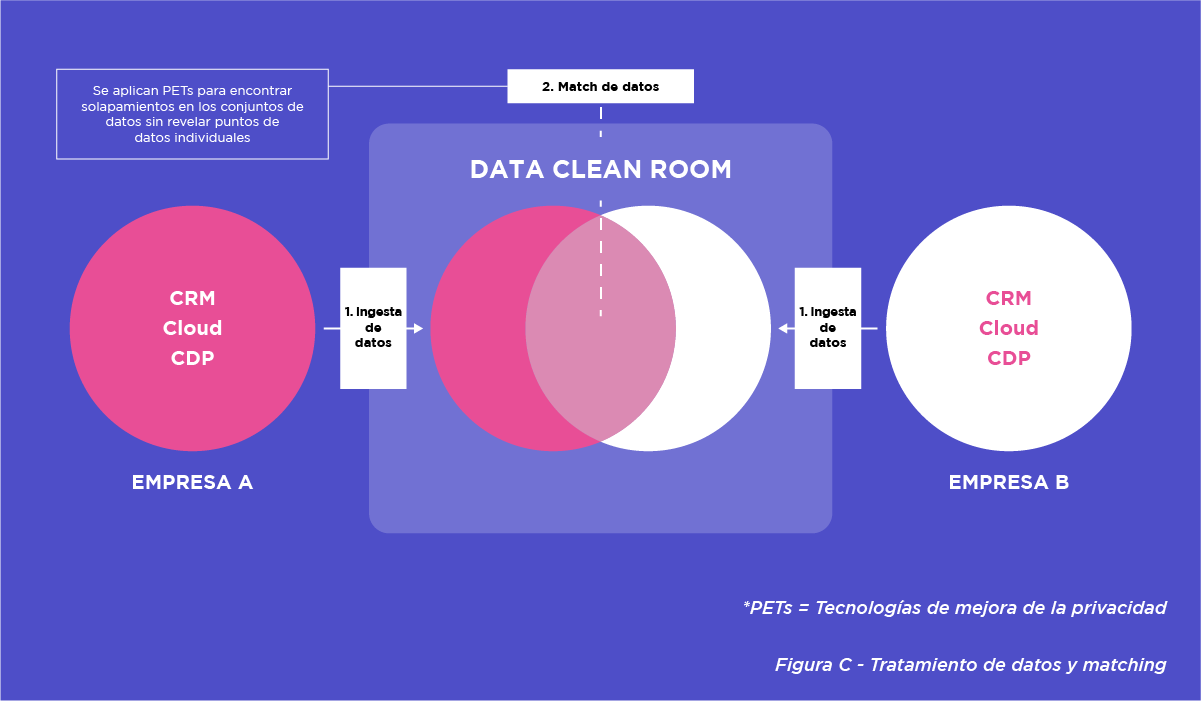
Procesamiento y match de datos
Una vez que los datos se han ingerido, el software de la Data Clean Room los procesa para permitir la coincidencia y el análisis. Esto implica alinear conjuntos de datos de diferentes fuentes basados en identificadores comunes. Antes del match, se aplican tecnologías de mejora de la privacidad (PETs) para garantizar que los datos se mantengan privados. Para que se produzca el match, se requiere un identificador común, como datos personales cifrados o IDs universales. El resultado protegido es lo que se usa para el match.
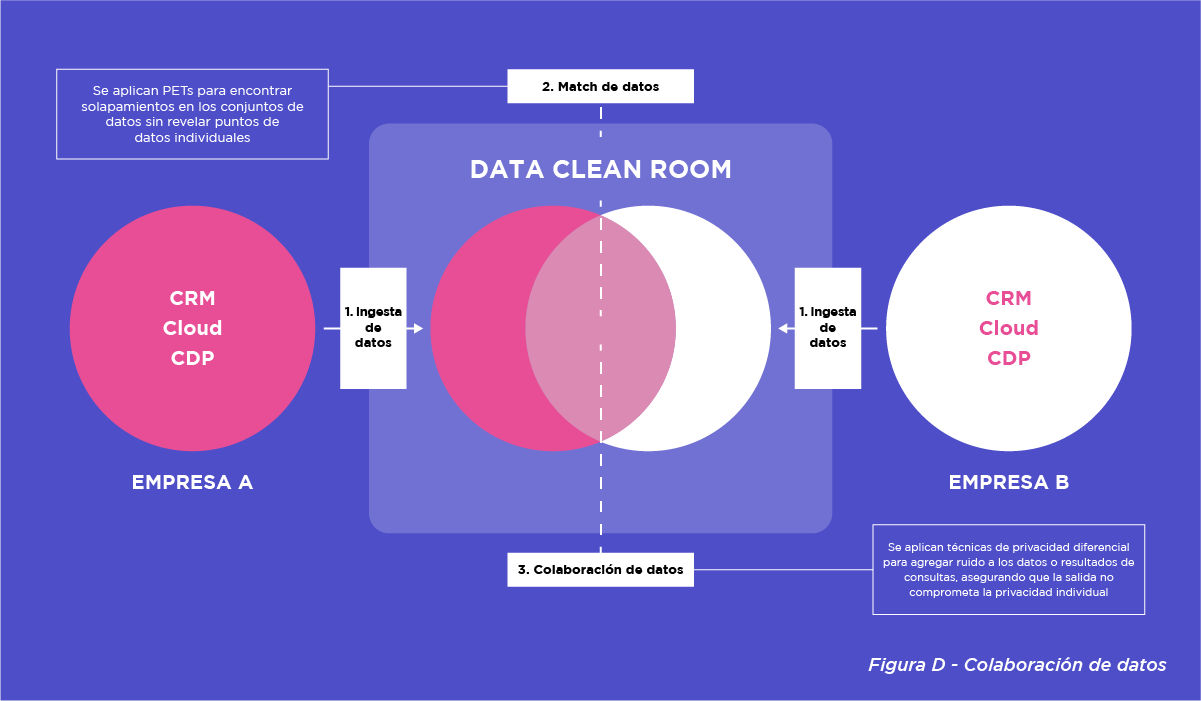
Colaboración de datos
Después del match, la DCR permite realizar varios análisis y casos de uso con los conjuntos de datos combinados. Esto puede ir desde agregaciones simples (como contar el número de registros coincidentes) hasta análisis más complejos (como segmentación de comportamiento o análisis de intención de compra). Los resultados se agregan a diferentes niveles para que no se revele la información individual de los usuarios. Se pueden aplicar técnicas de privacidad diferencial para añadir “ruido” a los datos o a los resultados de las consultas, asegurando que no se comprometa la privacidad individual.
Resultado para casos de uso de marketing
El paso final consiste en obtener los datos procesados y analizados en una forma útil para aplicaciones de marketing. Esto puede incluir segmentos de audiencia para publicidad, insights para visualización o datos coincidentes para ejecutar modelos. Lo crucial es que cualquier dato o insight extraído de la DCR cumpla con las regulaciones de privacidad y no revele PII. A menudo, los outputs agregados se envían a diferentes plataformas a través de integraciones nativas o API para diversos casos de uso.
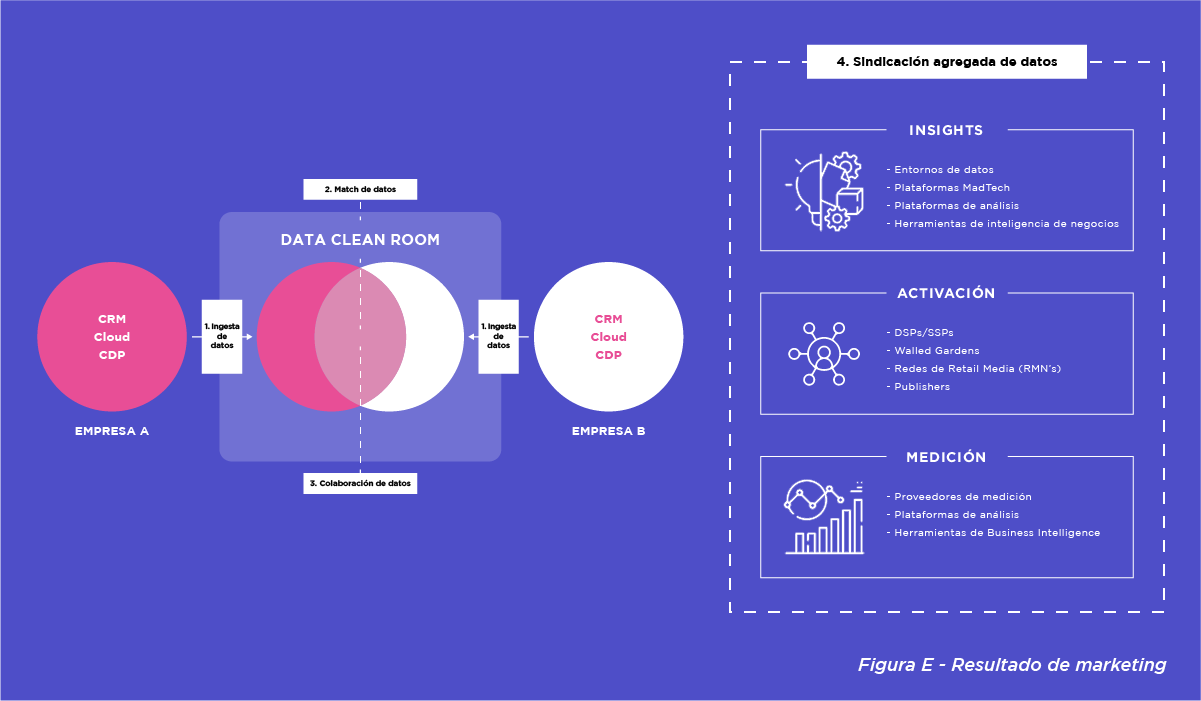
Un concepto clave es que los datos que la empresa A envía como salida son agregaciones de sus propios datos. A pesar de ser un colaborador, los datos de la empresa B no se combinan con los de la empresa A. En su lugar, la empresa A obtiene más información sobre qué segmentos de sus propios datos pueden utilizarse para sus casos de uso deseados.
Cómo es el match de datos en las Data Clean Rooms
Como explica el artículo de Skeleton Key, la zona de intersección del diagrama de Venn (Figura F) es donde se produce el match. Como ejemplo, supongamos que la Empresa A es una marca de gran consumo y la Empresa B, un servicio de streaming (como Disney+, ya que en realidad tienen su propia plataforma de DCR).
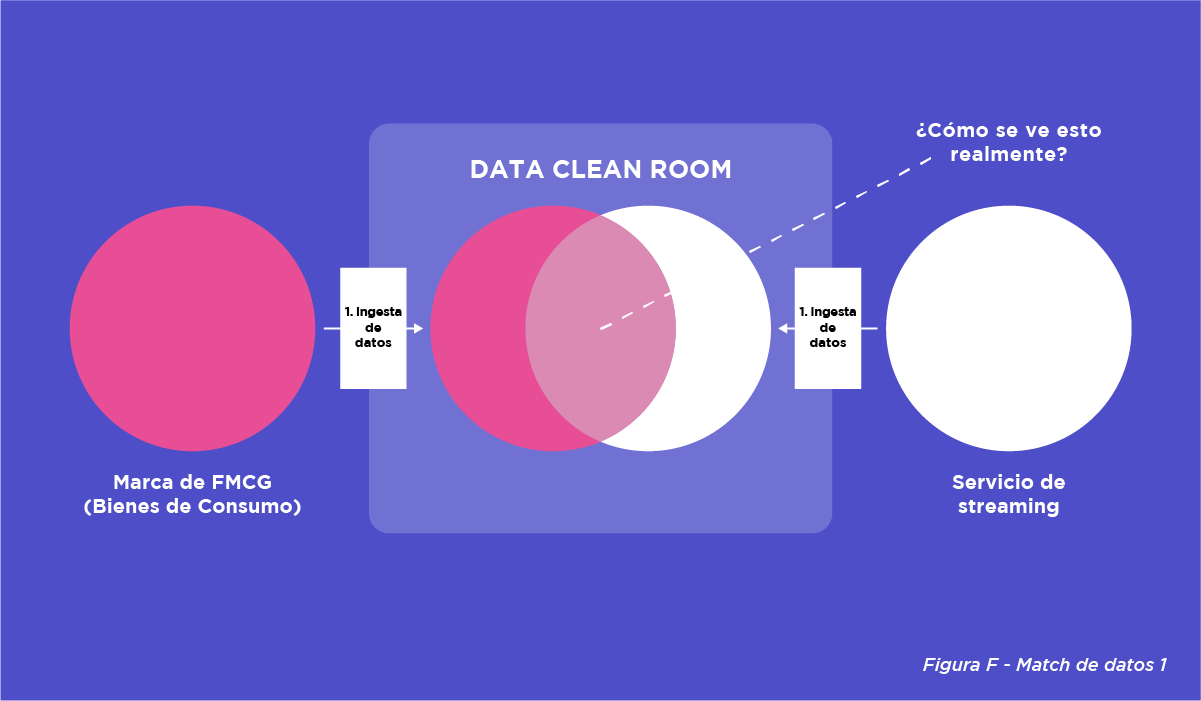
Supongamos ahora que la marca de bienes de consumo y el servicio de streaming han acordado realizar un análisis de solape con el objetivo de que la marca de bienes de consumo pueda segmentar mejor su audiencia frente a la programación del servicio de streaming.
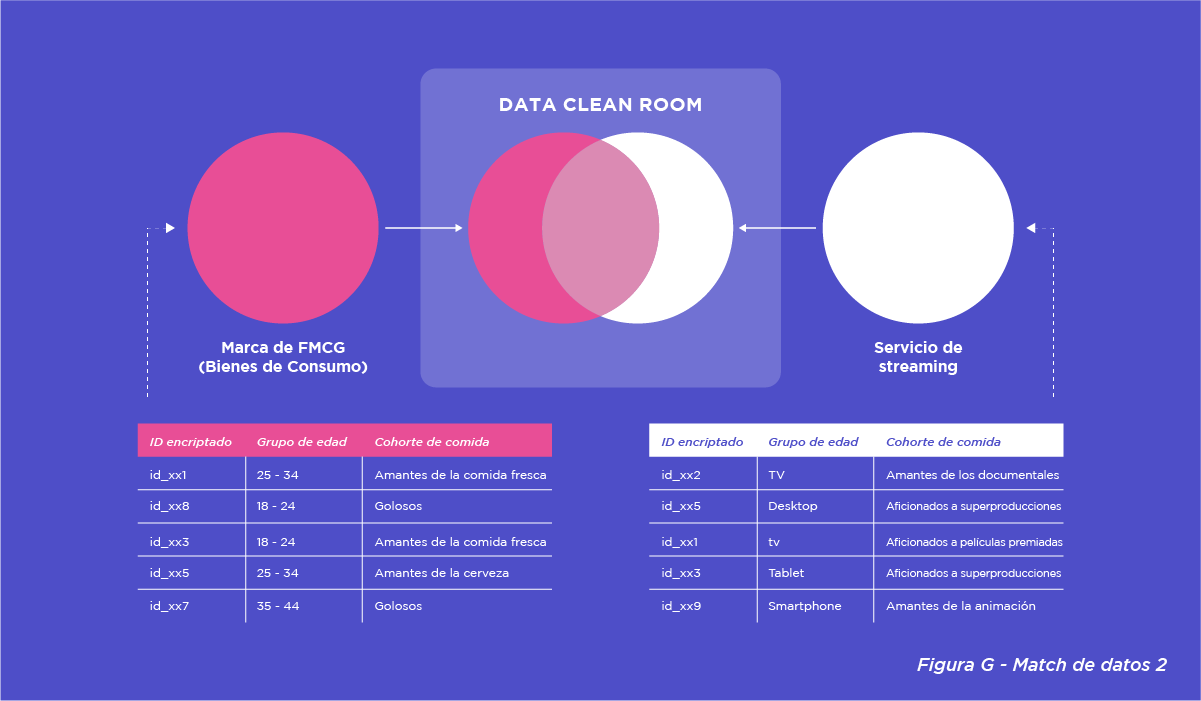
El conjunto de datos de la marca de bienes de consumo incluye los IDs de cliente codificados, el grupo de edad del cliente y la franja de alimentos a la que pertenece (esta segmentación se habría hecho con antelación). Por otro lado, el conjunto de datos del servicio de streaming también incluye los ID de usuario codificados (resueltos con el mismo formato que el de la marca de bienes de consumo), el dispositivo principal del usuario y el género según el contenido que ven (Figura G).
El resultado es una nueva tabla que contiene el número de clientes pertenecientes a diferentes combinaciones de alimentos y géneros. Como podemos ver (Figura H), aunque los usuarios individuales están incluidos en los datos incluidos en la DCR, sólo salen datos agregados. Para garantizar la privacidad de los datos y que no podamos identificar a usuarios individuales, las filas que contienen menos de 50 usuarios se suprimen.

Aunque las consultas del área de solape del diagrama de Venn son la función de match más común, también se utilizan otras consultas en función del caso de uso y de lo que esté permitido para garantizar que la colaboración se realiza preservando la privacidad. Esto se puede configurar en la propia DCR.
Conceptualización de casos de uso de las Data Clean Rooms
Las Data Clean Rooms permiten a una parte (empresa A) utilizar los datos de otra (Empresa B) o de otras para revelar nuevos datos sobre sus propios usuarios. En última instancia, este concepto desbloquea todos los casos de uso.
En otras palabras, en una colaboración DCR, la empresa A no está añadiendo o activando los datos de otra empresa B. La empresa A está utilizando los datos de la empresa B para revelar nuevos conocimientos sobre sus propios datos. Con esa información, la empresa A podrá desbloquear nuevos casos de uso.
Para ilustrarlo, vamos a ver algunos ejemplos de categorías de casos de uso en los que una parte establece las instancias de la DCR. Dicho esto, la mayoría de estos casos de uso también pueden ser iniciados por media owners o publishers.
Addressability y activación de audiencias
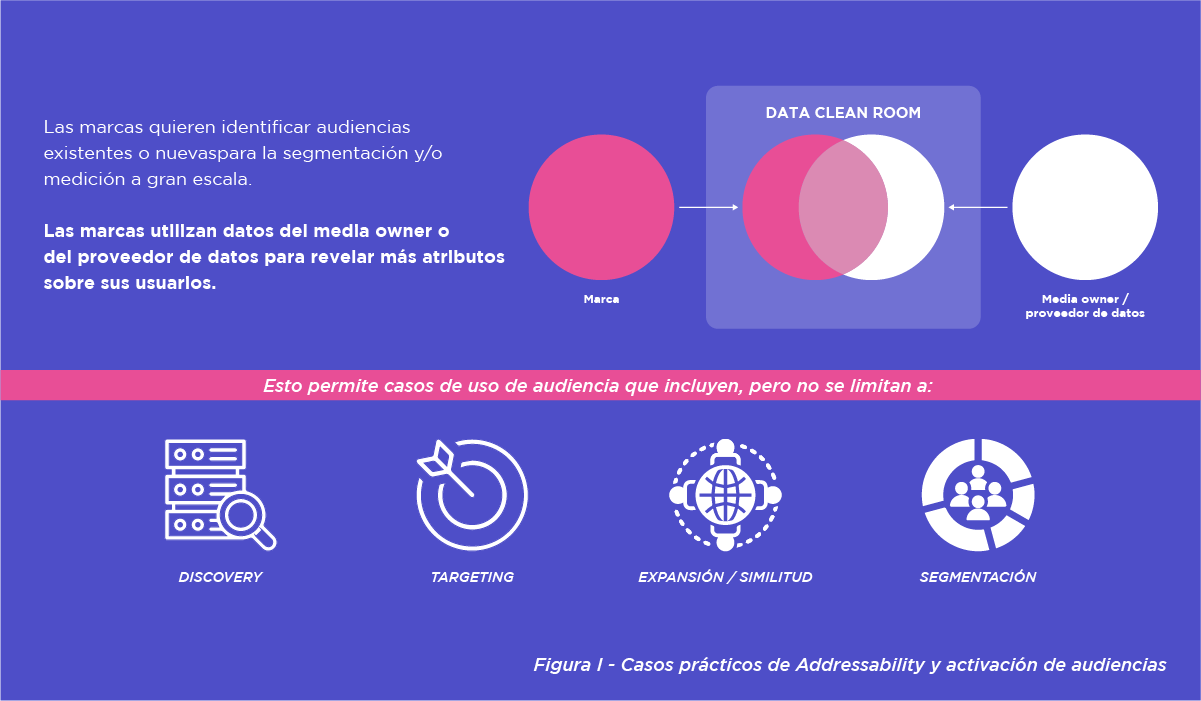
En este ejemplo (Figura I), la marca desea descubrir audiencias existentes o nuevas para la segmentación de medios y/o la medición a escala. La segunda parte en la colaboración es un media owner o un proveedor de datos. En estos casos, la marca utilizaría los datos proporcionados por el media owner o el proveedor de datos para revelar nuevos atributos sobre sus propios usuarios o clientes, que pueden servir de base para los casos de uso de las audiencias en sentido descendente señalados anteriormente.
Esto puede funcionar en ambos sentidos, ya que un media owner puede utilizar una DCR de manera similar para comprender mejor qué segmentos de audiencia en sus propiedades generan más compromiso.
Enriquecimiento de datos y generación de insights
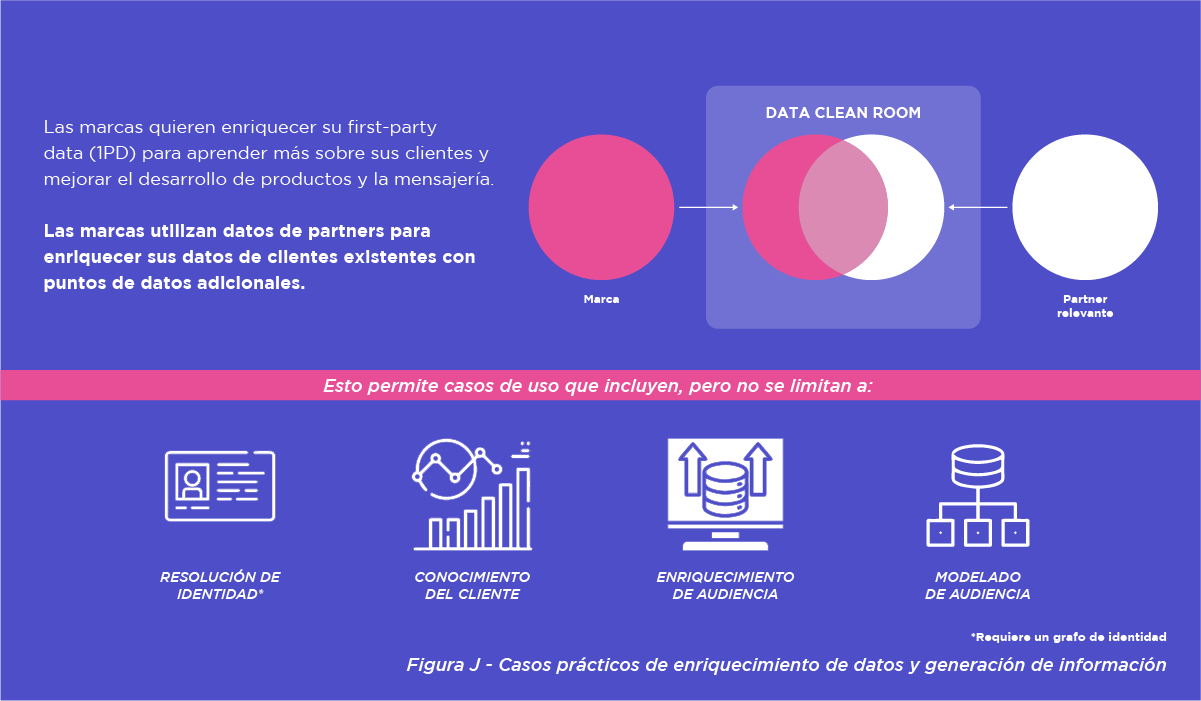
En este ejemplo (Figura J), la marca desea enriquecer su 1PD existente para comprender mejor a los clientes y mejorar desde el desarrollo de productos hasta la mensajería creativa y la planificación de medios. En este caso, la segunda empresa podría ser cualquier entidad con datos de valor añadido. En estos casos de uso, la marca utiliza datos de partners para enriquecer sus datos de clientes existentes, revelando nuevos atributos (demográficos, psicográficos, de comportamiento, etc.) para comprender mejor a sus clientes y optimizar los casos de uso destacados anteriormente.
Hay que tener en cuenta que los casos de uso que implican la resolución de identidades (es decir, el proceso de vincular diferentes puntos de datos a un individuo único) requieren el uso de uno o más gráficos de identificación, a los que las DCR suelen tener acceso.
Atribución, Medición, Optimización

En estos casos de uso (Figura K), la marca busca comprender mejor el impacto comercial y los beneficios generados por su inversión publicitaria. En este caso, la marca aprovecharía los datos de los media owners para revelar puntos de datos (por ejemplo, exposición a anuncios, participación, conversiones, ventas) necesarios para cuantificar mejor la eficacia de sus campañas de marketing y publicidad. Esto puede servir de base para los casos de uso posteriores enumerados.
El papel de los grafos de identidad en las Data Clean Rooms
El principal objetivo de los grafos de identidad (o ID graphs) en las DCR es mejorar los match rates entre conjuntos de datos de distintas partes. ¿Por qué es importante? Las DCR funcionan uniendo diferentes conjuntos de datos, normalmente utilizando algún tipo de ID de usuario como campo común. Más allá de las situaciones en las que los conjuntos de datos ya comparten el mismo identificador, la capacidad de unir conjuntos de datos dependerá de uno o varios grafos de identidad. Esto es crucial para la colaboración de datos, ya que las tasas de coincidencia (match rates) a menudo dictan la escala y la eficacia de los casos de uso.
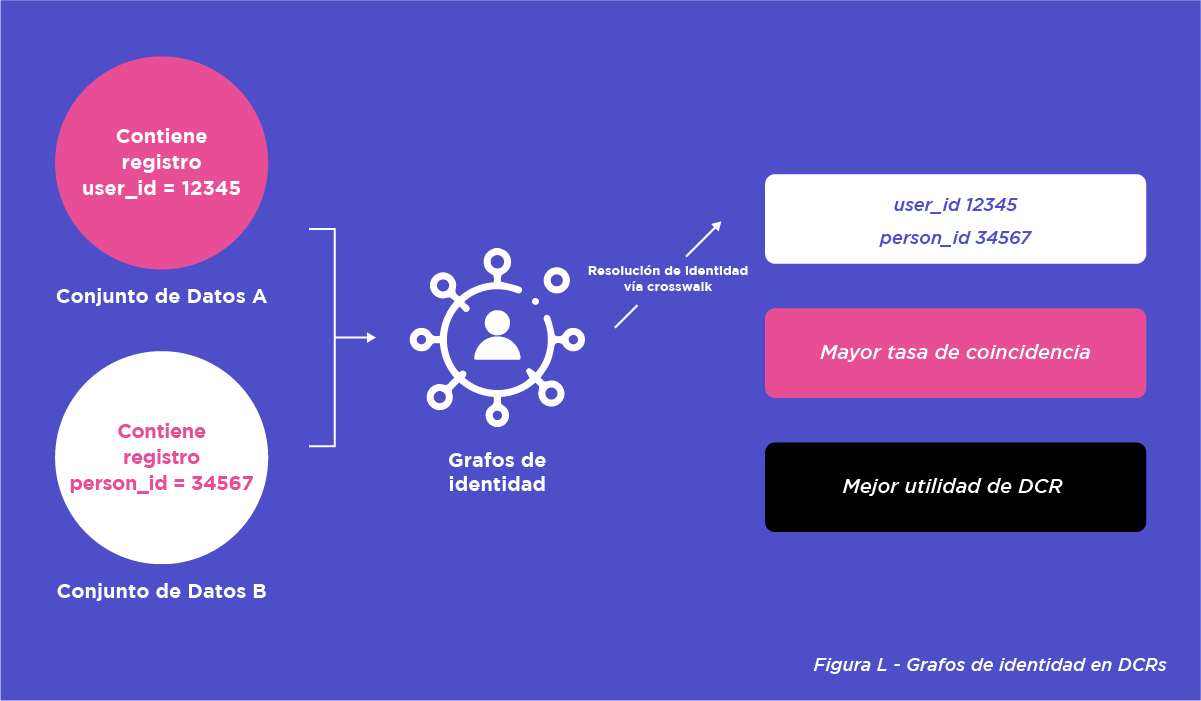
Por ejemplo (Figura L), supongamos que el conjunto de datos A contiene un registro de usuario con «user_id» = 12345, y el conjunto de datos B contiene un registro de usuario con «PersonID» = 34567. Mediante lo que se denomina un cruce de grafos de identidad (es decir, pasar de un conjunto de ID a otro), se determina que user_id: 12345 es igual a PersonID: 34567. Esto indica que la identidad entre esos registros ha sido «resuelta». Este proceso da como resultado una mayor tasa de match de datos, lo que se traduce en una mejor utilidad de la DCR.
Modelos de datos de usuario en Data Clean Rooms
Existen varios modelos en las DCR, que pueden ser usadas de dos maneras: “Construir” o “Importar” (Figura M).
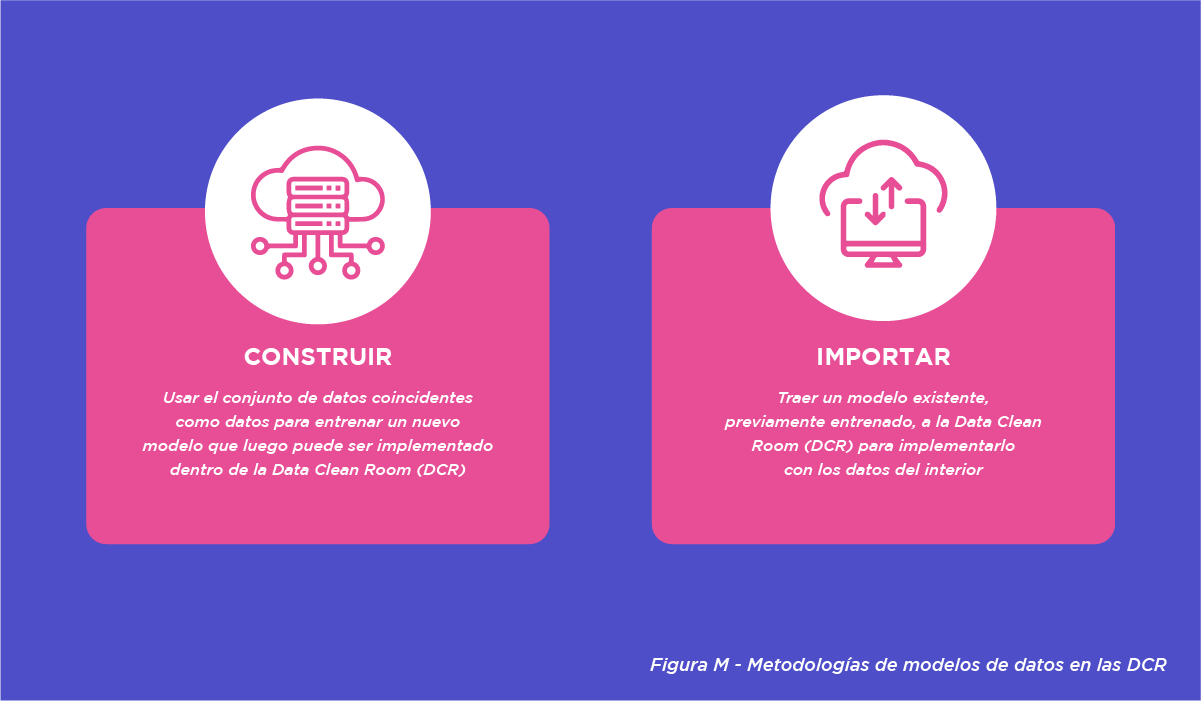
Para el modelo de “Construcción”, hay que tener en cuenta que los conjuntos de datos emparejados se pueden utilizar como cualquier otro conjunto de datos, siempre y cuando los datos no salgan del entorno DCR. El modelo creado puede desplegarse en los datos de clientes existentes dentro de la instancia de DCR, donde los científicos de datos pueden analizar los resultados para diferentes casos de uso. Igual que en todos los casos de uso, los datos agregados permiten obtener información, garantizando que no se exponga ninguna información de identificación personal. El análisis puede servir de base para la toma de decisiones, mejorar las estrategias de segmentación y aumentar la eficacia de las campañas de marketing.
En el caso de la “Importación”, una empresa introduce un modelo existente y ya entrenado (es decir, entrenado fuera de la DCR) para utilizarlo con los datos contenidos en la DCR. Los casos de uso que pueden habilitarse son potencialmente los mismos que los de los modelos creados dentro de una instancia DCR.
Llegados a este punto, la pregunta es: ¿las DCR facilitan realmente nuevos casos de uso o simplemente permiten que las estrategias de datos existentes se ejecuten de una forma más segura y respetuosa con la privacidad? El autor del artículo contesta: “La respuesta, hasta donde yo sé, es la segunda. Los casos de uso que hemos esbozado no son nuevos, pero las DCR proporcionan a los usuarios acceso a fuentes de datos 1P con las que colaborar que antes eran (prácticamente) imposibles”.
Esto nos lleva a otro concepto clave:
La mayoría de los casos de uso que permiten las DCR no son nuevos, pero proporcionan a los usuarios acceso a fuentes de datos 1P con las que colaborar que antes eran (prácticamente) imposibles.
Lo que hace "limpia" a una Data Clean Room
Las tecnologías de mejora de la privacidad (o PET), ya mencionadas en el artículo, son las que hacen que una Data Clean Room sea un espacio “limpio”, según el autor. Sin estas tecnologías, una DCR no sería más que un potente almacén de datos. Las DCR emplean un amplio conjunto de PET para garantizar que el análisis de datos y la colaboración entre las partes se produzcan de forma segura y respetando la privacidad.
A continuación se presentan algunas PET que se utilizan habitualmente en las DCR. Hay que tener en cuenta que las PET no son exclusivas de las DCR, ya que se utilizan en muchas otras tecnologías, tanto de publicidad como de tecnología avanzada.
Anonimización de datos: Elimina o altera los identificadores personales para que los datos no puedan asociarse a una persona sin información adicional. La anonimización garantiza que los datos utilizados en las DCR no puedan utilizarse para volver a identificar a las personas.
Seudonimización de datos: Sustituye los identificadores privados por identificadores falsos o seudónimos. A diferencia de la anonimización, la seudonimización permite cotejar o vincular datos con otros conjuntos de datos utilizando seudónimos, lo que facilita el análisis sin exponer las identidades personales.
Privacidad diferencial: Añade ruido a los datos o a los resultados de las consultas para impedir la identificación de individuos a partir del conjunto de datos. Esta es la principal PET que da cuenta de la agregación de datos en las DCR, ya que es particularmente útil en escenarios en los que es necesario compartir información estadística sin comprometer los puntos de datos individuales.
Cifrado “homomórfico”: Esta técnica permite realizar cálculos con datos cifrados sin necesidad de descifrarlos antes. Los resultados de estos cálculos se cifran y sólo pueden ser descifrados por el propietario de los datos. Esto permite procesar datos complejos en las DCR, garantizando al mismo tiempo la seguridad de los datos subyacentes.
Computación Multiparte Segura (SMPC): Permite a las partes calcular conjuntamente una función sobre sus inputs manteniendo la privacidad de las mismas. En el contexto de las DCR, esto permite a varias empresas aportar datos a un análisis o modelo compartido sin revelar sus conjuntos de datos individuales a los demás.
Pruebas de conocimiento cero: Método criptográfico que permite a una parte demostrar a otra que una afirmación es cierta sin información adicional. En las DCR, las pruebas de conocimiento cero pueden utilizarse para verificar la exactitud de los datos o cálculos sin exponer los datos subyacentes.
De nuevo, esto es sólo una muestra de alto nivel de algunas de las PET más comunes que se pueden encontrar en el contexto de las DCR. El objetivo es ilustrar que existe una amplia gama de técnicas y tecnologías que ayudan a proteger la seguridad y la privacidad de los datos al tiempo que permiten obtener nuevos conocimientos y tomar medidas basadas en los datos.
Las aplicaciones de las PET pueden calibrarse (hasta cierto punto).
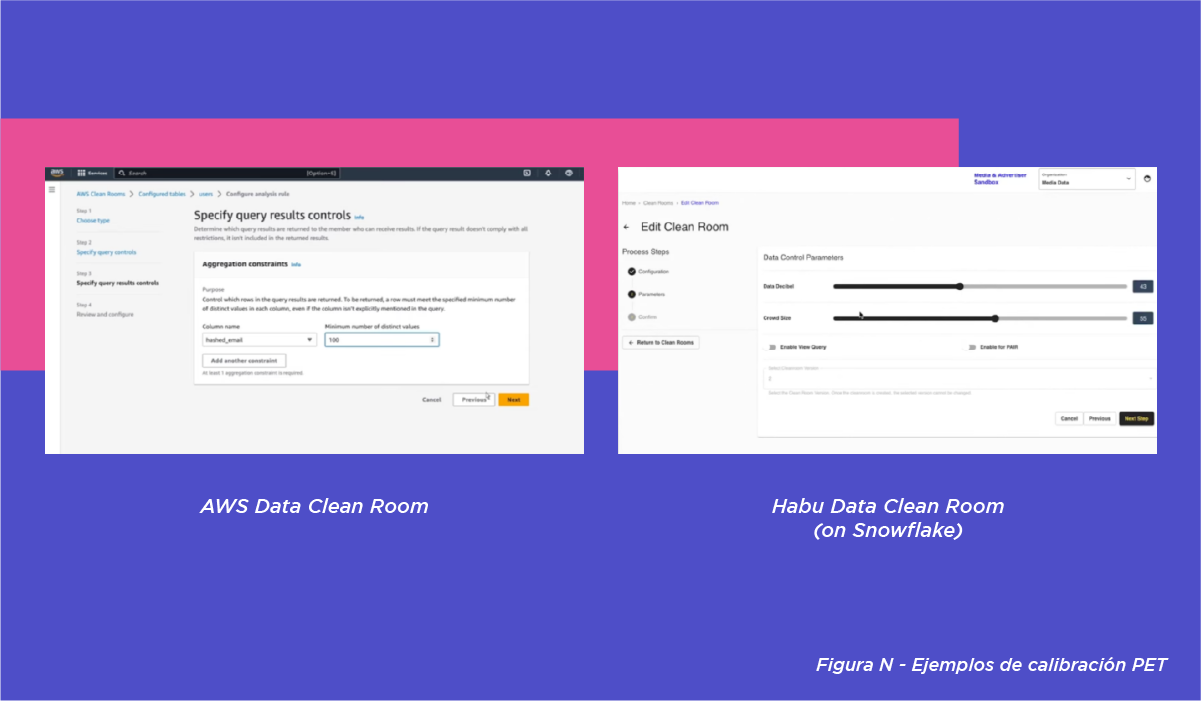
Por lo general, quien configura la instancia en la DCR puede calibrar el grado y la aplicación de las PET. Refiriéndose a la Figura N, se puede ver que en la DCR de AWS, los mínimos de agregación se pueden establecer en diferentes niveles, y en la DCR de Habu (en Snowflake), el usuario puede ajustar el Decibelio de Datos (inyección de ruido aleatorio) y el Tamaño de la Multitud (umbral mínimo para devolver datos).
Dicho esto, la flexibilidad para ajustar el nivel de las PET está sujeta a restricciones reglamentarias, técnicas y contractuales. Por ello, la colaboración entre usuarios, proveedores de DCR y asesores jurídicos es clave para encontrar el equilibrio óptimo entre la protección de la privacidad y la utilidad de los datos.
Categorías de Data Clean Rooms
Las Data Clean Rooms tienen distintos tipos: el gráfico O muestra algunos proveedores organizados por categorías. Estas categorías no son absolutas ni exhaustivas (algunos proveedores han evolucionado para estar en varias categorías, y lo que se ha incluido son sólo algunos de los ejemplos más destacados).

1. Pure Play
Se trata de empresas especializadas principalmente en soluciones DCR, cuyas características definitorias son la interoperabilidad, la flexibilidad y la neutralidad (es decir, pueden funcionar en las principales nubes). También incluyen funciones complementarias como la resolución de ID, el acceso a data marketplaces y la integración nativa s2s con sistemas mar/adtech. Todo esto amplía la funcionalidad y convierte a estos proveedores en una solución completa de gestión de datos.
Son ideales para clientes que buscan opciones de autoservicio en las que controlan la configuración de la DCR sin estar atados a ningún tipo de ID o tecnología.
2. Plataformas de datos
Se trata de DCR proporcionadas por plataformas de datos como Snowflake y Databricks. Son plataformas especializadas en workloads concretos (programas o aplicaciones que utilizan recursos informáticos para realizar tareas), como el almacenamiento de datos, el procesamiento de big data y la analítica. Están diseñadas para ser interoperables en diferentes nubes, lo que les permite integrarse y operar sobre la infraestructura proporcionada por AWS, GCP y Azure. Sin embargo, existen algunas limitaciones en relación con los pure players: por ejemplo, las instancias DCR de Snowflake requieren que todas las partes estén en Snowflake.
Son más adecuadas para usuarios técnicos, mientras que las pure players son más fáciles de usar, sin interfaz de usuario o con una interfaz de bajo código. Esto tiene sentido, ya que las plataformas de datos se centran en proporcionar una plataforma integral que atienda a ingenieros de datos, científicos y analistas, siendo las DCR una de las muchas funciones disponibles.
Las DCR proporcionadas por estas plataformas serían más beneficiosas para los clientes que ya las utilizan para sus necesidades de datos, ofreciendo así una profunda integración con las funciones existentes.
3. Medios de comunicación
Son DCR proporcionadas por medios de comunicación. Puede tratarse tanto de DCR de empresas de medios como Google y Amazon, como de publishers como Disney o NBCU. A diferencia de las DCR de plataformas de datos y pure play, estas funcionan como ecosistemas cerrados y centralizados en los que una de las partes participantes siempre será el propio proveedor de DCR: por ejemplo, Google Advertising, Amazon Ads (Ads Data Hub proporciona acceso a los datos de anuncios de Google, mientras que Amazon Marketing Cloud contiene las señales de Amazon Ads).
Los casos de uso son para anunciantes que quieren analizar y/o activar datos dentro del ecosistema de medios específico en el que están publicando anuncios. Los media owners que no son walled gardens pueden construir su propia plataforma DCR que contenga su columna vertebral de datos sobre otra infraestructura de Data Clean Room. Estas DCR son interoperables, ya que pueden funcionar en diferentes nubes, pero solo admiten casos de uso que utilicen datos de anuncios de sus mismas propiedades.
4. Híbridas
Esta categoría representa las DCR de proveedores que combinan elementos de diferentes categorías. Empresas como LiveRamp (que recientemente adquirió Habu) y AppsFlyer entran en esta categoría, mezclando características de las DCR puras con funciones especializadas de otras categorías. Por ejemplo, Habu/LiveRamp pueden ofrecer la interoperabilidad de las DCR puras junto con capacidades nativas de resolución de identidades. AppsFlyer también puede ofrecer una solución de DCR que funcione en diferentes entornos en la nube, al tiempo que aprovecha su principal punto fuerte en la atribución móvil, proporcionando información sobre el performance de la publicidad basada en aplicaciones (similar a las DCR de medios de comunicación).
Las DCR híbridas son idóneas para organizaciones que necesitan tanto las funciones especializadas de las plataformas de datos o las DCR de medios como la flexibilidad de las soluciones puras. Por ejemplo, una empresa que utilice AppsFlyer podría beneficiarse de su experiencia en atribución móvil y aprovechar también sus capacidades de DCR para una colaboración de datos más amplia. Del mismo modo, los clientes de Habu/LiveRamp pueden disfrutar de las ventajas de la resolución avanzada de identidades junto con funciones flexibles de colaboración de datos.
En la actualidad, los proveedores públicos de nubes también ofrecen servicios de DCR como parte de sus servicios de nube más amplios (Figura P). Obviamente, están diseñados para vivir dentro de dichos servicios en la nube y crear sinergias con ellos, y están dirigidos a los usuarios existentes de sus plataformas.

Aunque esto puede resultar un poco confuso, lo que está claro es que existe un tipo de DCR para cada tipo de usuario y organización, lo que demuestra lo importante que se ha vuelto la colaboración de datos hoy en día.
Además, las Data Clean Rooms pueden ser centralizadas o descentralizadas.
En el primer caso, las DCR descentralizadas (o a veces denominadas distribuidas), no significa que una única instancia de DCR esté dividida en diferentes dispositivos o servidores. Más bien se refiere al hecho de que la cognición DCR está descentralizada y se mueve entre múltiples instancias DCR (cada una propiedad de un socio dentro de una única colaboración de datos).
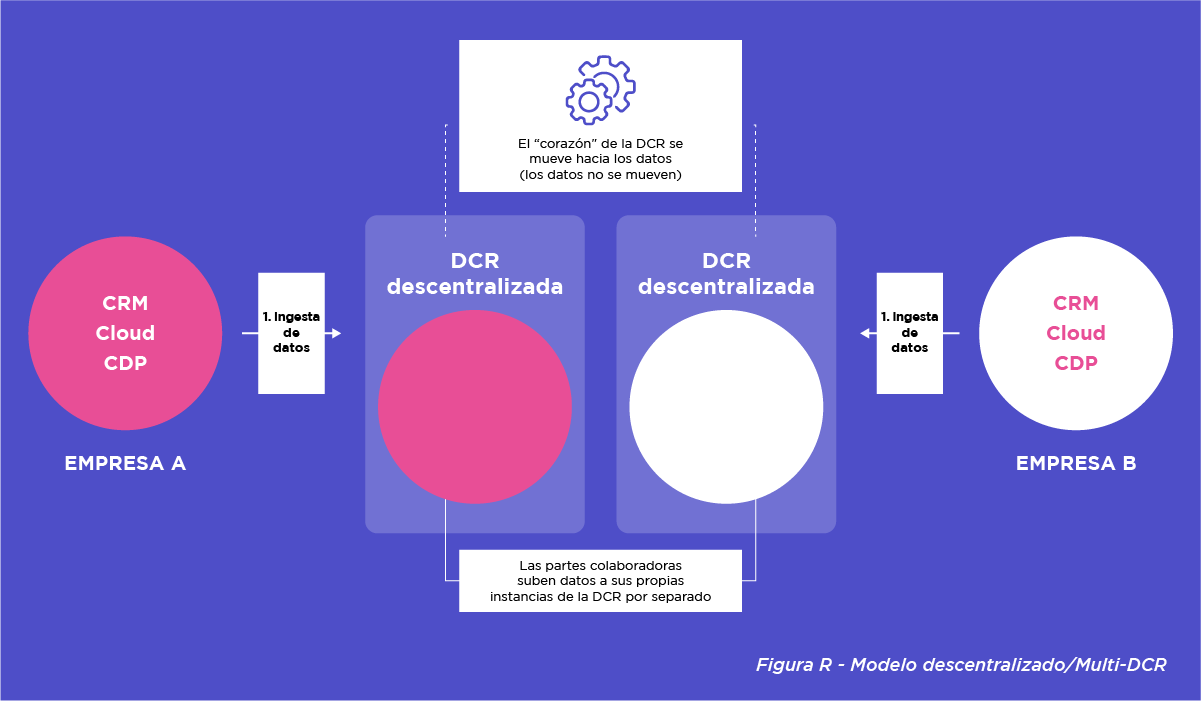
Esto sería un «modelo multi-DCR». La cognición se refiere aquí a los mecanismos que permiten el procesamiento de datos, el cotejo, las PET, etc. Como tal, lo que conforma una DCR no es necesariamente una única instancia de DCR, sino más bien las instancias de DCR combinadas de las partes que componen una colaboración de DCR determinada.
Como ya se ha mencionado, las DCR centralizadas son más sencillas, ya que en ellas la cognición está centralizada en una única instancia de DCR compartida por los colaboradores. La figura Q representa un modelo de una DCR centralizada. En este caso, las partes cargan sus datos en una única instancia DCR compartida. En otras palabras, aportan sus datos a la cognición.
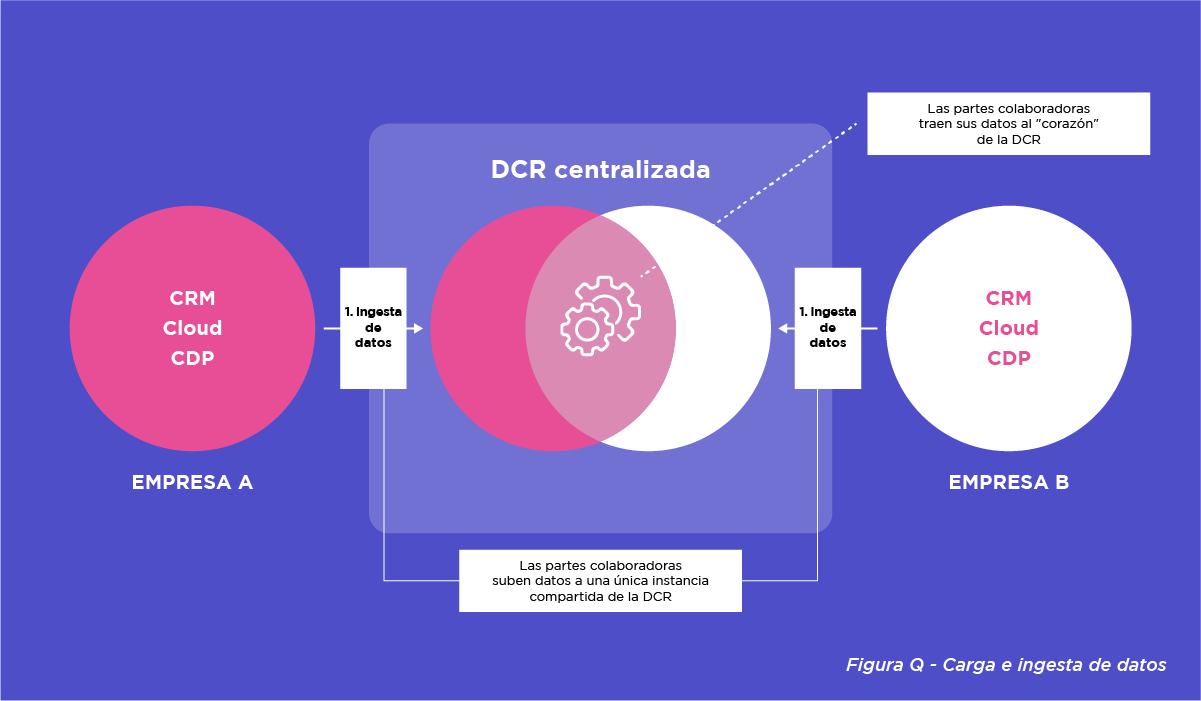
La figura R, por su parte, representa un modelo de DCR descentralizado. En este caso, las partes cargan sus datos en su propia instancia DCR (es decir, no compartida). Otra forma de entenderlo es como un modelo de DCR múltiple. La cognición va al lugar donde se sitúan los datos (por lo que los datos en sí no se mueven). En otras palabras, cada socio mantiene sus datos en su propio entorno DCR sin necesidad de trasladarlos al entorno DCR de su socio colaborador.
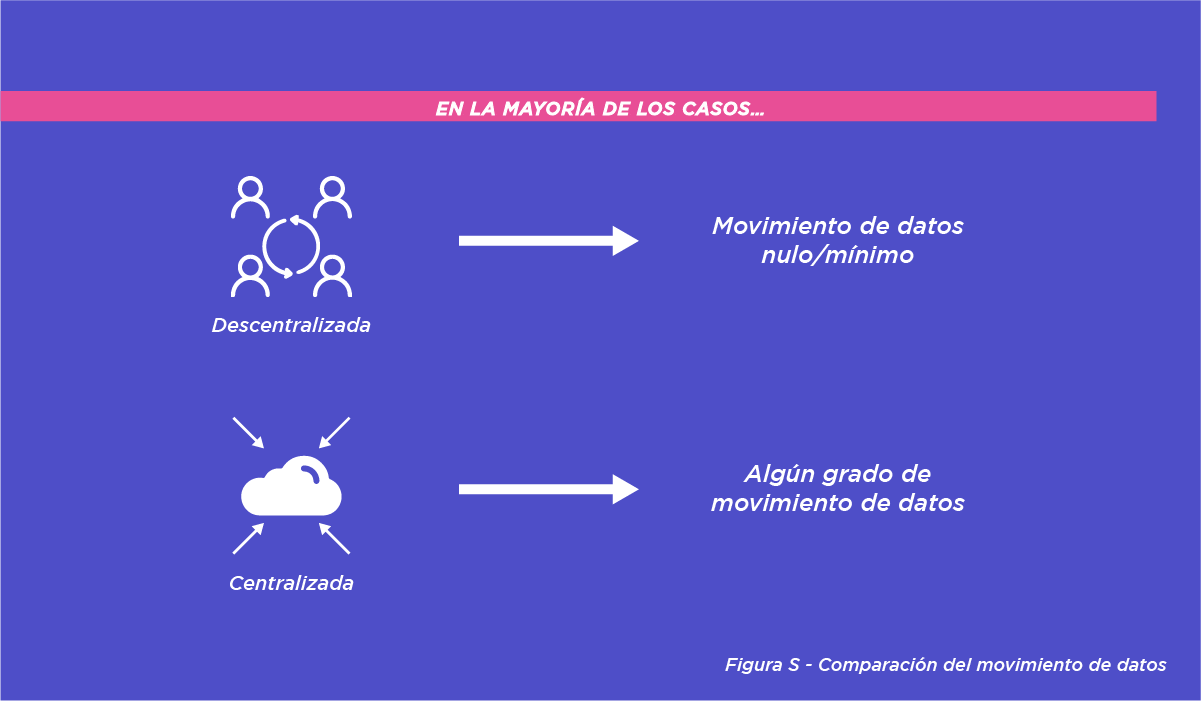
Si nos remitimos a la figura S, en la mayoría de los casos, las DCR descentralizadas están asociadas a un movimiento de datos nulo o mínimo. Por otro lado, las DCR centralizadas se asocian normalmente con cierto grado de movimiento de datos (es decir, usuarios que cargan sus datos en una instancia DCR compartida). Dicho esto, esto no significa que todas las DCR sin movimiento sean descentralizadas o que las DCR con movimiento de datos sean necesariamente centralizadas. Puede haber excepciones, configuraciones combinadas y otros matices.
Detalles adicionales
Nueva fuente de ingresos para los propietarios de medios
Anteriormente, se ha mencionado que las DCR no permiten necesariamente “nuevos” casos de uso sino que conceden a las organizaciones un acceso a fuentes de datos first-party que antes era imposible. Además, las DCR también proporcionan una vía hacia una nueva fuente de ingresos para los propietarios de medios, que poseen first-party data a escala y diferenciada.
Se ha hablado mucho de la creciente importancia del first-party data en el panorama de los datos y de cómo podría proporcionar ingresos a este tipo de publishers: el uso de DCR para engrasar los casos de uso de colaboración de datos con las marcas es un ejemplo de ello (véase la Figura T para ver ejemplos de media owners que han aprovechado esta ventaja).

Esta vía podría ser especialmente beneficiosa para los media owners no-walled gardens, ya que las DCR ofrecen una forma de desagregar los datos del inventario de medios que antes no existía. Los beneficios también se extienden a los anunciantes, ya que ahora tendrían los medios para acceder a medios first-party que en el pasado habrían sido prácticamente imposibles. Ello supondría una fuente de ingresos para los walled gardens que no cambiaría el juego. En este sentido, hay quien cree que, con el tiempo, las DCR sustituirán a los DMP y quizá a los CDP de los publishers para estos casos de uso.
¿Plataforma o producto?
Hablando de DCR, DMP y CDP, una pregunta que se plantea a veces es si las DCR son una “plataforma” o un ”producto”. Es una pregunta justa a la luz de las diferentes categorías de DCR que hemos cubierto anteriormente.
Plataforma: Cuando la DCR es el producto central (o uno de los productos centrales) de la plataforma o suite.
Producto: Cuando la DCR es uno de los muchos servicios o funciones que ofrece la plataforma o suite.
Desglosamos esto más en detalle en la figura U:
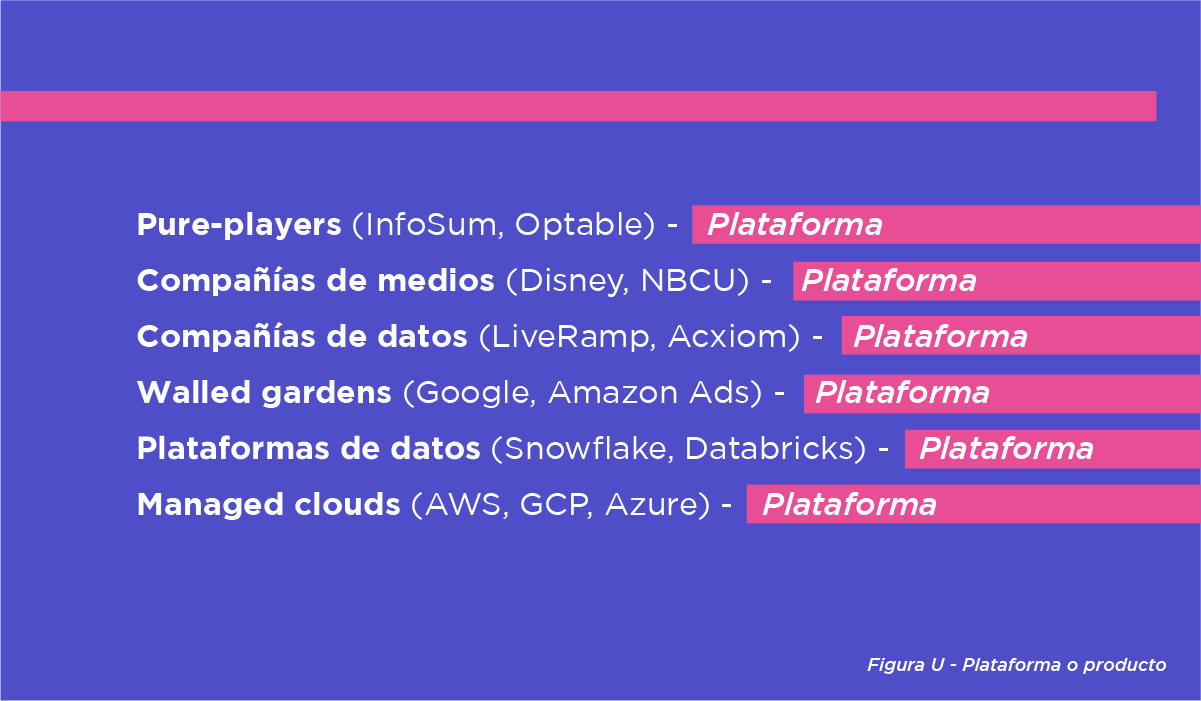
Pure Player: Es lógico pensar en los proveedores pure play como plataformas, ya que contienen funciones nativas, datos de socios e integraciones mar/adtech que amplían sus funcionalidades hasta hacerlas comparables a las de los CDP.
Empresas de medios de comunicación: También entran en la categoría de plataformas, pero por motivos diferentes. En este caso, se debe a que están configuradas para que los colaboradores (normalmente anunciantes) introduzcan sus conjuntos de datos en el entorno de DCR de la empresa de medios para permitir casos de uso que utilicen los datos de medios de la empresa.
Empresas de datos: En el caso de empresas como LiveRamp y Acxiom, tiene sentido pensar en las DCR como productos dentro de su suite. Dicho esto, sus ofertas de DCR suelen estar potenciadas por otros proveedores. Por ejemplo, LiveRamp adquirió Habu para reforzar su oferta de DCR existente, mientras que el producto de DCR de Acxiom está impulsado por Snowflake.
Walled Gardens: Para empresas como Google y Amazon, las DCR son claramente productos. Por ejemplo, Ads Data Hub es un producto dentro de su oferta más amplia de anuncios/nube, mientras que la DCR de Amazon Ads es una de las cinco funciones diferentes de Amazon Marketing Cloud.
Plataformas de datos y Managed Clouds: En este caso, las DCR pueden considerarse productos dentro de un conjunto de servicios. Por ejemplo, la oferta de DCR de Snowflake es una característica que puede activarse desde su conjunto de productos más amplio. Con AWS, las DCR son sólo uno de los muchos productos ofrecidos dentro de sus características de infraestructura de nube y workloads.
¡Felicidades! ¡Si has leído hasta aquí, ahora sabes más sobre Data Clean Rooms que la mayoría de las personas en la industria!