
Los Superpoderes de la DATA: #1 OVERLAP
Vamos a intentar explicar de forma amena y sencilla los superpoderes de la data science y del análisis de los datos en el universo de la publicidad con el objetivo de mejorar nuestro conocimiento sobre clientes y prospects. Hoy empezamos con el primer artículo de la serie, aclarando el concepto de #overlap.
#1 OVERLAP
¿Cuál es el cliente ideal? ¿Dónde podemos encontrarlo? Estas son dos cuestiones fundamentales que debemos hacernos a la hora de elaborar nuestras estrategias de prospecting. No es tarea sencilla responderlas y, a veces, partimos de ideas preconcebidas sobre nuestro target que pueden limitar el área de búsqueda. Afortunadamente, podemos contar con técnicas de data analysis muy potentes que nos permitirán abrir la mente y mejorar el conocimiento de nuestro público objetivo.
Uno de los análisis de datos más comunes en publicidad es el overlap. Consiste en cruzar una audiencia (por ejemplo, los visitantes de nuestra web) con una base de datos externa proporcionada por un proveedor de datos (publisher, retailer o anunciante). Esta base de datos está compuesta generalmente por segmentos de usuarios o clusters agrupados en función de sus intereses o de su perfil sociodemográfico. Para realizar este análisis, es necesario que nuestra audiencia y la base de datos compartan el mismo tipo de identificador (cookie o ID).
¿Cómo funciona? El análisis de overlap calcula el volumen de usuarios en común entre nuestra audiencia y los diferentes clusters de la base de datos para identificar los más afines a la marca.
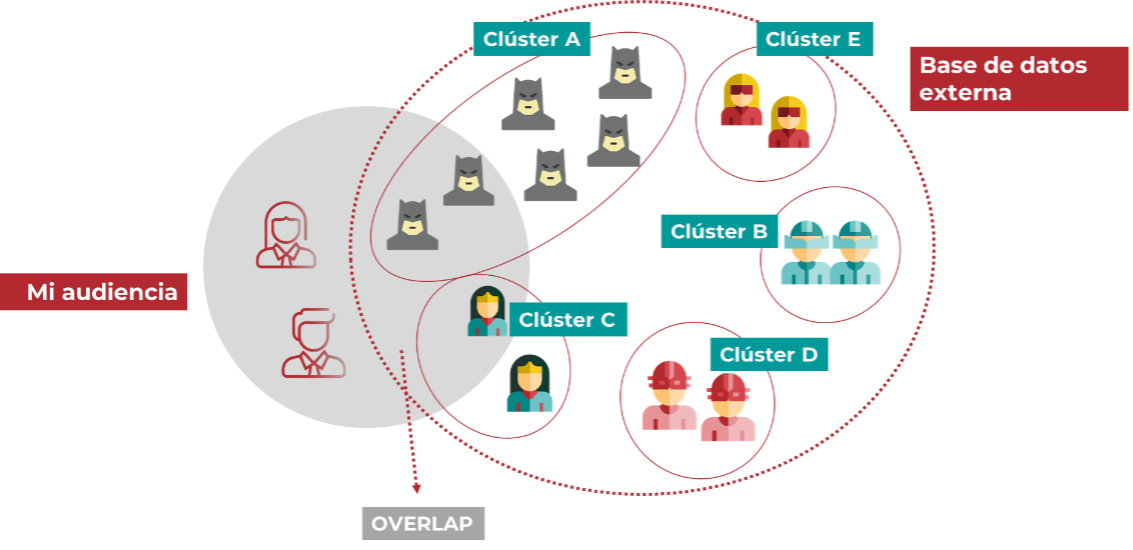
En este gráfico, lo ejemplificamos solapando nuestra audiencia con una base de superhéroes. Los clusters Batman y Wonder Woman parecen más afines a mi marca. Sin embargo, el cálculo del número de usuarios en común no es suficiente para interpretar los datos porque existe un sesgo importante. Al cruzar nuestra audiencia con toda la base de datos externa, tenemos más probabilidad de encontrar usuarios en común con los clusters más grandes de la base (el cluster de Batman en este caso), pero ello no significa necesariamente una afinidad. Para prevenir este sesgo, tendremos que calcular un score de afinidad que tenga en cuenta la representatividad del cluster en la base de datos.
Para los amantes de “las mates”, calculamos la fórmula del score de afinidad:

Pongamos que la base de superhéroes cuenta con 100.000 usuarios, de los cuales el cluster Batman tiene 5.000 y el cluster Wonder Woman 200. Y que mi audiencia suma un total de 100 usuarios, de los cuales 10 coinciden con el cluster Batman y otros 10 con el cluster Wonder Woman.
El resultado obtenido sería el siguiente:
· Score de afinidad del cluster Batman = 0.04
· Score de afinidad del cluster Wonder Woman = 16.67
Claramente, el cluster Wonder Woman es más afín a mi marca. Hay 16.67 veces más probabilidades de que mi audiencia esté en el cluster Wonder Woman que otro usuario de la base de datos elegido al azar. En cambio, el cluster de Batman (cuyo score es inferior a 1) no tiene una afinidad con mi audiencia, a pesar de contar con más usuarios en común.
Para ir más allá, podemos representar estas conexiones gráficamente mediante el network visualization. Pero no os contamos más por hoy, ya lo descubriréis en el próximo artículo de esta serie sobre Los superpoderes de la Data...

Sophie Algarte, DATA Director de Avante Evolumedia