
#8: La atribución son los padres: El futuro de la medición y la atribución
Ahora que las cookies de terceros tienen los días contados, surgen muchas preguntas sobre los pilares básicos que sustentarán el marketing digital en la era cookieless. Entre estas preguntas, las que siguen: ¿Qué ocurrirá con la atribución y la medición? ¿Qué soluciones, actuales o futuras, se acabarán implantando?
Y es que, al menos a mí (ya sabéis que tengo una visión cuanto menos particular 😀), me da la impresión de que tendremos que volver a recuperar los videos donde el Conde Draco de Barrio Sésamo nos enseñaba a contar, pero esta vez sin cookies, porque el Monstruo de las Galletas se las habrá comido todas.
En poco tiempo, muchos medios, anunciantes, proveedores de datos y plataformas tecnológicas deberán reevaluar y reestructurar sus enfoques para la recopilación de datos, la orientación de audiencias, la medición y la atribución. Todas esas actividades cambiarán y, junto con ellas, las formas en que rastreamos y medimos la publicidad y el comportamiento del usuario y, en consecuencia, cómo se optimizan las campañas y los sitios web.
Como resumen de forma fantástica en el blog de Clearcode, donde también participa Johanna Álvarez (toda una crack y amiga), el escenario futuro esperado para la atribución se está construyendo principalmente utilizando cuatro pilares:
El oligopolio de los datos. El acceso a los datos será controlado por los walled gardens de Google, Apple, Facebook y Amazon.
Mayores integraciones de datos. Los acuerdos directos y las integraciones para acceder a 1st Party Data compensarán parte de la pérdida de datos causada por la ausencia de cookies de terceros.
1st Party Data autenticada. Las direcciones de correo electrónico con hash y otros identificadores únicos se utilizarán ampliamente para crear un sustituto de las cookies de tercera parte.
Pérdida de granularidad (user-level). Será más difícil obtener datos granulares a nivel de usuario.
¿Qué soluciones hay encima de la mesa?
Vamos al grano. Ahora quiero hablaros de algunos desarrollos en los que está trabajando la industria Adtech y también empresas de atribución con el fin de ofrecer continuidad (o al menos una pseudo-continuidad) a sus soluciones de medición y atribución en un escenario sin cookies de tercera parte.
En mi opinión, es importante hablar de las propuestas concretas y animar a toda la industria a ofrecer su máximo esfuerzo y ánimo de cooperación con el fin de que un servidor, dentro de muy poco, se vea obligado a actualizar esta publicación para añadir 10 soluciones más (como poco).
Privacy Sandbox (Google)
En este punto específico, no entraremos en detalle ahora, porque ya lo hicimos en uno de los capítulos de Indentity War y podéis acceder al enlace a releer o leerlo por primera vez (¿todavía no lo has hecho?).
Privacy Preserving Ad Click Attribution (Webkit)
Webkit (el motor del navegador web que impulsa a Safari), ha propuesto una solución que permitirá a los anunciantes ejecutar una atribución de clics “amigable” con la privacidad. La propuesta de Webkit se llama Privacy Preserving Ad Click Attribution.
La atribución de clics según el Privacy Preserving Ad Click Attribution consta de tres pasos:
Almacenar los clics de anuncios. Esto lo hace el sitio web que aloja el anuncio en el momento de hacer clic en el anuncio.
Hacer coincidir las conversiones con los clics de anuncios que se almacenaron. Esto se hace en el sitio web al que navegó el anuncio como resultado del clic. Las conversiones no tienen que ocurrir inmediatamente después de un clic y no tienen que ocurrir en la página de destino específica, sino en el mismo sitio web.
Enviar datos de atribución de clics en anuncios. Esto lo hace el navegador después de que una conversión coincida con un clic en un anuncio.
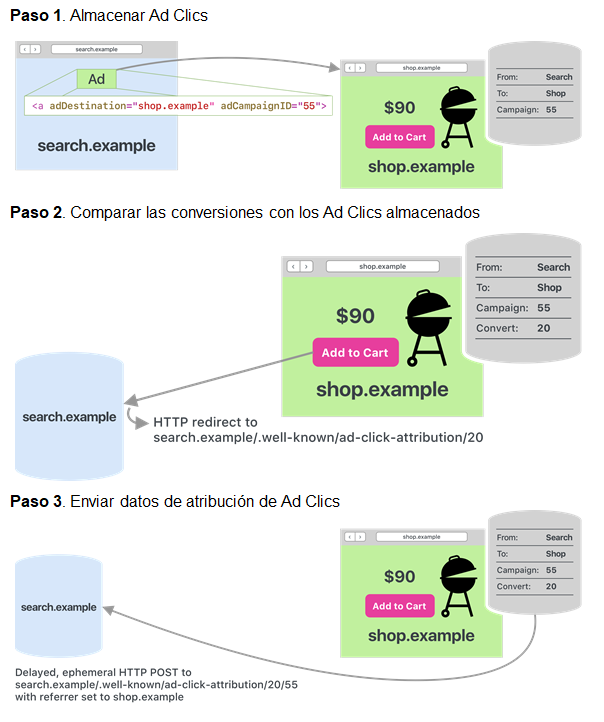
Pasos del Privacy Preserving Ad Click Attribution.
La solución de atribución de clics en anuncios que pone encima de la mesa Webkit es muy estricta en las cuestiones de privacidad ya que no permite el seguimiento de usuarios entre sitios, pero sí proporciona una alternativa (el tiempo dirá si lo suficientemente válida) para medir la efectividad de los anuncios online. Todo se centraliza desde el navegador, en este caso Safari, y se ejecuta en el dispositivo (¿os suena?), lo que significa que el proveedor del navegador no puede ver en qué anuncios se hace clic o qué compras se realizan.
Como podéis concluir, todo esto suena muy parecido a cómo se espera que pueda funcionar el estándar de atribución y medición de Privacy Sandbox propuesto por Google Chrome, es decir, la atribución la haría el navegador en lugar de una empresa de terceros a través de cookies y no se basará en la identificación de personas. Así que, nuevamente, las empresas de AdTech serán dependientes de un navegador, en este caso de Safari.
Cross-Media Measurement Framework (WFA)
Hace unas semanas, la World Federation of Advertisers (WFA) emitió una declaración y una propuesta técnica para un marco de medición cross-media. Fue el resultado de una revisión y un debate que se ha alargado un año entre participantes, como Google, Facebook, Twitter, grupos industriales como ANA y MRC y grandes anunciantes como Unilever, P&G y PepsiCo.
Esta propuesta incluye cuatro componentes principales:
Paneles.
Data de Censo e Identidad.
Private Reach y Estimación de frecuencia.
API y Dashboards.
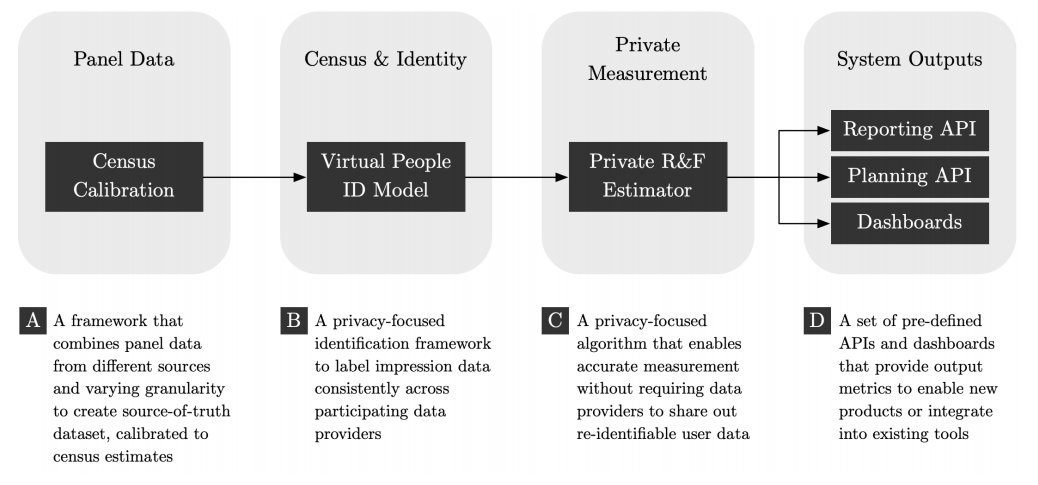
Los 4 pilares de la solución Cross-Media Measurement
Es decir, la propuesta combina un “panel” de usuarios con datos del censo proporcionados por los medios participantes, así como un procesador de datos de terceros neutral. Asimismo, también se habla sobre varios "virtual IDs" y sobre procesos de modelado avanzados (que están vagamente definidos), con el objetivo de proporcionar una forma para que las plataformas que no comparten un ID común (¿te acuerdas del Universal ID? puedan construir una versión de uno.
En mi opinión, la propuesta está muy centrada en campañas digitales que tengan en cuenta el canal de TV, ya que aspectos que se proponen recuerdan a las técnicas de medición de ese canal. Por ejemplo, este framework se apoya en gran medida en paneles que incluso llega a denominar como “arbiters of truth” (¡ahí queda eso!). Los paneles son un herramienta de medición de medios que ya se está promoviendo por players como Nielsen, pero que tienen un problema ya que requieren una gran inversión tanto en la implantación como en el mantenimiento. Y en la propuesta de la WFA no queda claro quién financiará dichos paneles. Si es que ya lo decía AC/DC en su canción Moneytalks:
Come on, come on, love me for the money
Come on, come on, listen to the moneytalk
Además, en el pasado, soluciones similares de paneles han tenido problemas para recopilar ciertos tipos de datos entre dispositivos, en concreto de aplicaciones móviles.
Otro aspecto clave del framework cross-media e implícito es que dos grandes walled gardens (Google y Facebook ya que han participado) están abiertos a intercambiar de datos de alguna forma (exacto, tampoco se detalla). Aunque seguramente serán datos agregados como se ya se informó por parte de otros participantes. Pero bueno, menos da una piedra.
Como otra de las bases de este nuevo método, está la propuesta para vincular las impresiones que ocurren en diferentes medios (que no comparten un ID común) con el fin de calcular el alcance y la frecuencia.
De manera general, se describe un proceso de asignación de un “Virtual ID” (VID) a cada impresión. Este VID tiene como objetivo identificar a un usuario único. ¿Pero os preguntaréis y cómo se asigna? Pues aquí entramos en el genial mundo de la magia arcana ya que no se dan demasiados detalles. Además ahora parece que utiliza cookies (y otros datos) en su primera versión, y en el futuro pasará a ser una solución sin cookies basada en los datos propios del medio (publisher). Al final, como resultado, se crea un registro pseudo-anonimizado con un VID adjunto para cada impresión, superpuesto con datos demográficos, al menos cohortes de edad y género, extrapolados del panel.
Después, cada medio individual realizará agregaciones en "sketches”. Es decir, grupos de VID que pertenecen al mismo segmento demográfico o de interés para una campaña. En definitiva es algo que recuerda bastante a las propuestas de Google Privacy Sandbox, porque además estos sketches tampoco permitirán la identificación a nivel usuario.
En el penúltimo paso, cada medio envía sus sketches a un servicio independiente (no tenemos el honor de conocer quién es) que se encargará de combinar y de-duplicar los VID para así proporcionar una estimación del alcance y la frecuencia en toda la campaña. La WFA tiene una propuesta para este estimador de frecuencia y alcance privado publicada en Github. Y si os gusta tanto el barro como a mí y sois tan frikis, veréis que en el enlace se detallan estructuras de datos y algoritmos vectoriales de conteo, que ahora parece que son una tendencia o casi un elixir mágico para el futuro de la medición.
Por último, los resultados se proporcionan a través de un API y dashboards, que permiten tanto la elaboración de informes como la planificación de medios.

Overview del WFA Cross-Media Measurement
En definitiva, si leéis toda la documentación, estaréis de acuerdo conmigo que es una propuesta ambiciosa que tiene piezas adecuadas para continuar trabajar pero que, sin duda, como todo el futuro cookieless pasará por niveles “heroicos” de cooperación. De hecho, sus próximos pasos son las pruebas de validación y viabilidad que lidera ISBA en el Reino Unido y ANA en Estados Unidos.
Hay mucho en juego
Muchas empresas de nuestra industria confían en las cookies para decidir dónde colocar los anuncios y a quién impactar, así como para tomar decisiones comerciales que afectan el tamaño de su base de clientes, los ingresos y las ventas.
Las marcas, los medios, los proveedores de tecnología y las soluciones de datos deben unirse, colaborar y encontrar nuevas soluciones. Todos necesitan un asiento en la mesa para definir y priorizar casos de uso comercial críticos, fomentar políticas públicas que satisfagan las necesidades de una nueva industria centrada en la privacidad.
Hasta ahora, el jurado ha estado deliberando sobre la forma que deben tomar los enfoques futuros, y la industria solo está de acuerdo en que debe ser sin cookies. Los anunciantes deben tener cuidado de asegurarse de que los datos que recopilan se manejen de manera responsable. El enfoque debe estar en el uso de tecnología que sea segura, que recopile datos sin ser vinculados fácilmente con el individuo y que no viole su privacidad.
Cumplir con las nuevas expectativas de los consumidores y los requisitos de privacidad electrónica no tiene por qué negar el seguimiento, la toma de decisiones y la atribución efectiva; si la industria prioriza los derechos de las personas y aprovecha las soluciones inteligentes. Esto significa desarrollar continuamente tecnología innovadora que impulse mensajes personalizados que aporten un valor claro y que sea muy estricta y transparente en lo que respecta a la privacidad y gestión de los datos, pero que por otro lado, alentará a los usuarios y/o clientes a compartir datos con la industria de la publicidad digital.