
El equilibrio entre latencia y rendimiento: por qué los servicios rápidos son lentos y viceversa
Hoy recuperamos un artículo, que aunque es de hace unos años, nunca pasa de moda: "El compromiso latencia/rendimiento: por qué los servicios rápidos son lentos y viceversa"
No podemos tener a la vez alto throughput y baja latencia en nuestra arquitectura.
Latencia vs Rendimiento
Petición rápida frente a lotes
Sistemas de datos operativos frente a sistemas de datos analíticos
De acuerdo, los sistemas operativos responden lo más rápido posible, optimizados para la latencia, y los sistemas analíticos ejecutan grandes agregaciones en conjuntos de datos masivos, optimizados para el rendimiento.
Pero, ¿y si necesitamos consultas analíticas con una latencia muy muy muy muy baja? ¿Snowflake? ¿Redshift? ¿Clickhouse? ...La respuesta correcta es ... Tinybird ... 🐦
Por fin me estoy poniendo a leer ese libro de DevOps del que todo el mundo habla maravillas, “Site Reliability Engineering: How Google Runs Production Systems”. Mi veredicto hasta ahora: es bastante bueno.
Este es uno de los primeros pasajes que me llamó la atención, del capítulo 3: Abrazar el riesgo:
“El usuario de baja latencia quiere que las colas de solicitudes de Bigtable estén (casi siempre) vacías para que el sistema pueda procesar cada solicitud pendiente inmediatamente después de su llegada. (El usuario preocupado por el análisis offline está más interesado en el rendimiento del sistema, por lo que quiere que las colas de peticiones nunca estén vacías. Para optimizar el rendimiento, el sistema Bigtable nunca debe estar inactivo mientras espera su próxima solicitud.”
Esta es una visión profunda y general. Cuando leí este pasaje, mi última década de sufrimiento abyecto de repente se centró en mí.
Cuando digo "sufrimiento abyecto", me refiero por supuesto a la administración de ElasticSearch. Cuando un sistema de almacenamiento como ElasticSearch tiene que servir tanto a cargas de trabajo de baja latencia como de alto rendimiento, está garantizado que se ponga feo. Este hecho es muy importante, por lo que estoy dedicando esta entrada a la exploración de las relaciones entre la latencia, rendimiento y capacidad desde una perspectiva de colas. Espero que estas relaciones se te queden tan grabadas como a mí.
El compromiso entre rendimiento y latencia
Consideremos un servicio que responde a peticiones. Como ejemplo, digamos que es un servicio que toma como entrada una foto de un perro y devuelve una foto de ese perro con un sombrero tonto.

Fuente: Blog de Dan Slimmon
Como casi todos los servicios (excepción: Tourbillon), nuestro servicio sólo puede gestionar un número determinado de solicitudes por segundo [para poner sombreros a los perros (RPSTPHOD)]. Llamaremos a este número su capacidad. Si tenemos 200 procesos dedicados a poner sombreros a los perros, y los perros tardan una media de 400 milisegundos en hacer el habdash, la capacidad teórica del sistema es de (200) / (0,4s) = 500 sombreros por segundo
Consideremos ahora los dos tipos de usuarios que dependen de nuestro servicio:
In situ. En un momento dado, estos usuarios tienen una única foto de perro que requiere un sombrero lo antes posible. Tal vez utilicen nuestro servicio como soporte de un sitio web que genera una única foto de sombrero de perro por carga de página, y quieren que su página se cargue rápidamente. A estos usuarios les interesa sobre todo la rapidez con la que pueden ponerle un sombrero a un perro. En una palabra: latencia.
Masivos. Estos usuarios suelen tener conjuntos de datos masivos que quieren procesar lo más rápido posible. El ejemplo más obvio sería el de un organismo policial que quisiera comparar su gran base de datos de fotos de mascotas con las imágenes de vigilancia de un perro concreto robando un banco mientras llevaba un sombrero. A los encargados de poner sombreros a los perros de forma masiva no les importa la latencia de cada uno de ellos, sino el rendimiento que pueden alcanzar. En otras palabras: cuánto pueden acercarse a la capacidad teórica de nuestro servicio de 500 sombreros por segundo.
Pero aquí está el problema: ningún cluster de servidores puede ser óptimo para ambos tipos de usuarios. Y cuanto mejor hacemos el servicio para un tipo de usuario, peor lo hacemos para el otro.
Las necesidades de los usuarios in situ
Para minimizar la latencia para nuestros usuarios in situ (sin perder ninguna de sus peticiones), tenemos que asegurarnos de que siempre haya un procesador libre cuando llegue su petición. Si no lo conseguimos, las nuevas solicitudes tendrán que ponerse en cola mientras esperamos a que se abra un hueco, lo que aumentará la latencia. El sistema necesita algo de "holgura".
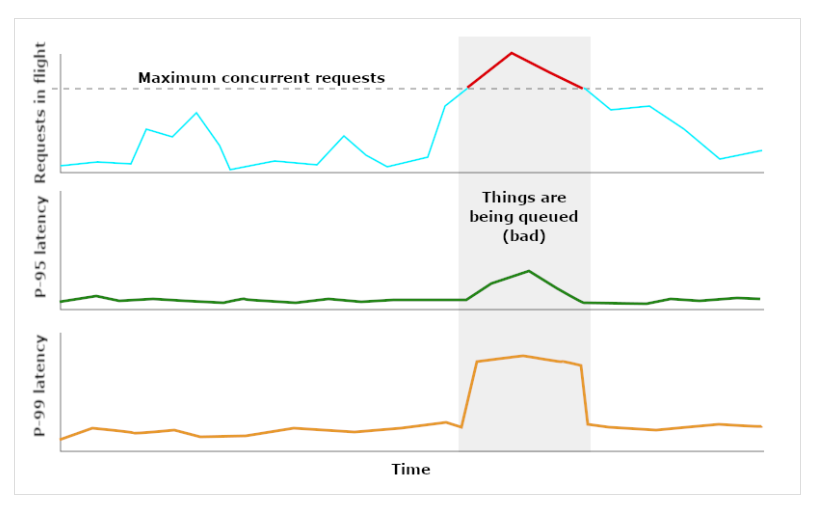
Fuente: Blog de Dan Slimmon
Como necesitamos holgura, no queremos que el rendimiento se acerque nunca a la capacidad. Cuanto más nos acerquemos a la capacidad de nuestro sistema, más drásticamente se dispararán las latencias.
Las necesidades de los usuarios masivos
En cambio, a nuestros usuarios masivos no les importa tanto la latencia de las peticiones. Algunas de sus peticiones individuales pueden tardar segundos, minutos o incluso horas en completarse. Lo que les importa es la rapidez con la que nuestro servicio puede procesar todo su conjunto de datos. En otras palabras, les importa que el rendimiento se acerque lo más posible a la capacidad.
Esto significa que, siempre que se esté ejecutando un trabajo, los "sombrereros de perros" quieren que no haya (prácticamente) ninguna holgura. Todos los procesadores deben estar activos en todo momento. En consecuencia, el tamaño de nuestras colas explotará en cuanto comience el trabajo, y nuestras colas permanecerán ocupadas hasta que el trabajo esté casi terminado.
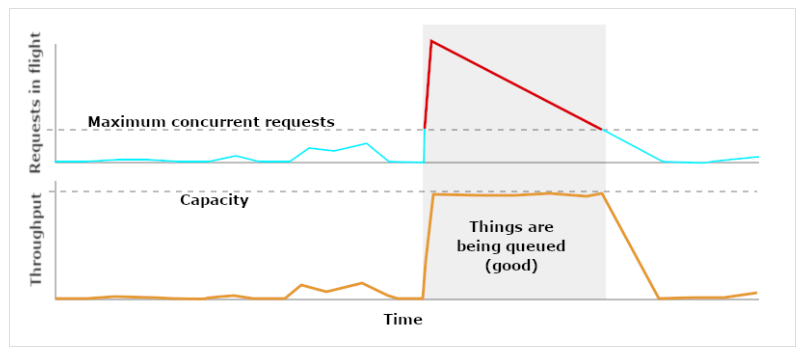
Fuente: Blog de Dan Slimmon
En este caso, queremos que nuestras colas estén llenas siempre que haya un trabajo masivo en ejecución. Cualquier otra cosa daría un rendimiento inferior al óptimo.
Dividir el cluster
Las necesidades de los usuarios puntuales y de los usuarios masivos son incompatibles. Un grupo necesita una latencia mínima, mientras que el otro necesita el máximo rendimiento.
Si ambos grupos utilizan el mismo cluster, tendremos graves problemas. Las latencias de los usuarios in situ variarán mucho en función de si hay un trabajo masivo en curso, y los tiempos de trabajo de los usuarios masivos variarán en función del número de usuarios in situ que estén utilizando el sistema. Por mucho que escalemos o modifiquemos los parámetros de ajuste, ninguno de los dos grupos obtendrá lo que necesita. Y lo que es peor, estaremos atrapados en un tira y afloja perpetuo entre las prioridades de estos dos grupos.
Así que dividamos nuestro cluster en dos: uno de "baja latencia" y otro de "alto rendimiento". Y dejemos que nuestros usuarios elijan el adecuado para su caso de uso. De este modo, tendremos unas expectativas mucho más claras sobre el rendimiento y las características de escalado de nuestro servicio, y evitaremos el frustrante tira y afloja de prioridades que caracterizaba a nuestro cluster de uso mixto.
La división no tiene por qué ser completa. En lugar de tener dos clusteres totalmente separados, podríamos tener algún tipo de equilibrador de carga que reserve una parte de nuestra flota para el tráfico de baja latencia y asigne trabajos masivos a segmentos dedicados del cluster. Los detalles de cada solución variarán. Lo que importa es que las tareas en el momento y las masivas no utilicen el mismo conjunto de recursos.
Una vez que hayamos dividido nuestro cluster, ¿cuáles deberían ser las características de rendimiento de los nuevos clusters? ¿Qué aspecto tendrán sus paneles gráficos cuando estén sanos, o cerca de la capacidad, o por encima de la capacidad? En un próximo post, utilizaremos más razonamiento de colas para responder a estas preguntas. Así que prepárate para ello.
Fuente: Dan Slimmon, Site Reliability Engineer